
Why is explaining machine learning models important?
AI systems are often regarded as “black box” entities that are intricate and challenging to interpret. In such a scenario, how can designers and users of these systems place trust in them or hold them accountable?
There’s a significant expectation that AI systems should offer clear and comprehensible explanations for their decisions and behaviours. This becomes especially critical to ensure that AI systems are seen as trustworthy, accountable, and aligned with human values.
The main focus in machine learning projects is to optimize metrics like accuracy, precision, recall, etc. We put effort into hyper-parameter tuning or designing good data pre-processing. What if these efforts don’t seem to work?
Machine learning and deep learning models are treated as “black box” implements, where we don’t know what is happening inside.

Fortunately, there is a tool that can help to find out WHY the model is making a specific decision for each sample. SHAP (SHapley Additive exPlanations) can help us to answer this question.
The concept of SHAP is based on game theory.
The “game” in this context represents prediction, and “players” correspond to features of observation. The “method” relates to checking how the removal of one of the “players”/features will affect the results of “the game”/prediction. The main advantage of SHAP is that it can explain a wide range of models, from Decision Trees and SVMs, to Convolutional Neural Networks and even Transformers.
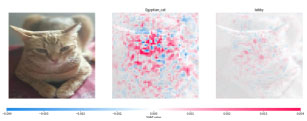
For example, on the MNIST dataset, you can check how individual pixels affect the end prediction of each class.

This plot explains ten outputs (digits 0-9) for four different images from the MNIST dataset
The plot above represents how each pixel of four input images (in the first column) influences a prediction for each one of ten output classes (numbers 0 to 9; each number is represented by its own column). Every red coloured area indicates a pixel which increases the probability of a particular class occurring. On the other hand, the blue color indicates pixels which decreases the probability. When the point is blue, a model mistake has been made.
Thanks to this, we can take a picture and see what part of the image the model is “looking” at. This gives us the potential to compare what the model is learning with our own knowledge. It can be helpful when the results of the model are poor.
Read Also: Decimal Point Analytics: Implementing Machine Readable Regulation for Competitive Advantage
My experience with this tool
One of the models, which I have trained was achieving poor results because it was focused on identifying patterns in the background and not on the main object of the image. Plotting SHAP values of each pixel in the image helped us to recognise this problem. We couldn’t have done that without this tool. The solution for the problem turned out to be finding a good combination of input image augmentation and filtration. As a result, we managed to improve the key metrics’ results for model performance. Additionally, SHAP values allowed us to check if patterns learned by the model were aligned with objects in real images.
medium.com/…./interpreting-deep-learning-models-for-computer-vision
The importance of a model’s explainability
Explainable AI (XAI) is a burgeoning field of science that is developing in parallel with new model architectures. Efforts are directed at creating solutions for interpreting the decisions made by models and also at refining methods to present, visualize, and make explanations more accessible to humans.
Whilst every ML model predictions affects human lives, it is important to understand the reasoning and logic behind how those predictions were made. For example, when you are applying for a job and you get a decision about your hiring, you can ask for feedback and an explanation of that decision. But what if the decision were made by a model? This is why we need explanatory methods for machine learning models: especially today, when they are getting more and more popular in use, and our lives are affected by cases like spam filters or recommendations of places that you can go on vacation.
To keep people safe, we should be able to explain AIS decisions for cases in critical areas such as medicine, criminal justice and driverless cars. In healthcare, it is important for doctors to know why the model reached a certain conclusion, especially when specialists don’t see any signs of illness but the model suggests a diagnosis. This problem was recognized with the IBM Watson supercomputer. Its predictions were unfounded from doctors’ points of view and many specialists disagreed with the computer’s decisions. The problem was that no one could ask the computer for an explanation of its decisions.




{kind=link}